01 Dec 2018
Sequential Attend, Infer, Repeat: Generative Modelling of Moving Objects
Sequential Attend, Infer, Repeat: Generative Modelling of Moving Object
We present Sequential Attend, Infer, Repeat (SQAIR), an interpretable deep generative model for videos of moving objects. It can reliably discover and track objects throughout the sequence of frames, and can also generate future frames conditioning on the current frame, thereby simulating expected motion of objects. This is achieved by explicitly encoding object presence, locations and appearances in the latent variables of the model. SQAIR retains all strengths of its predecessor, Attend, Infer, Repeat (AIR, Eslami et. al., 2016), including learning in an unsupervised manner, and addresses its shortcomings. We use a moving multi-MNIST dataset to show limitations of AIR in detecting overlapping or partially occluded objects, and show how SQAIR overcomes them by leveraging temporal consistency of objects. Finally, we also apply SQAIR to real-world pedestrian CCTV data, where it learns to reliably detect, track and generate walking pedestrians with no supervision.
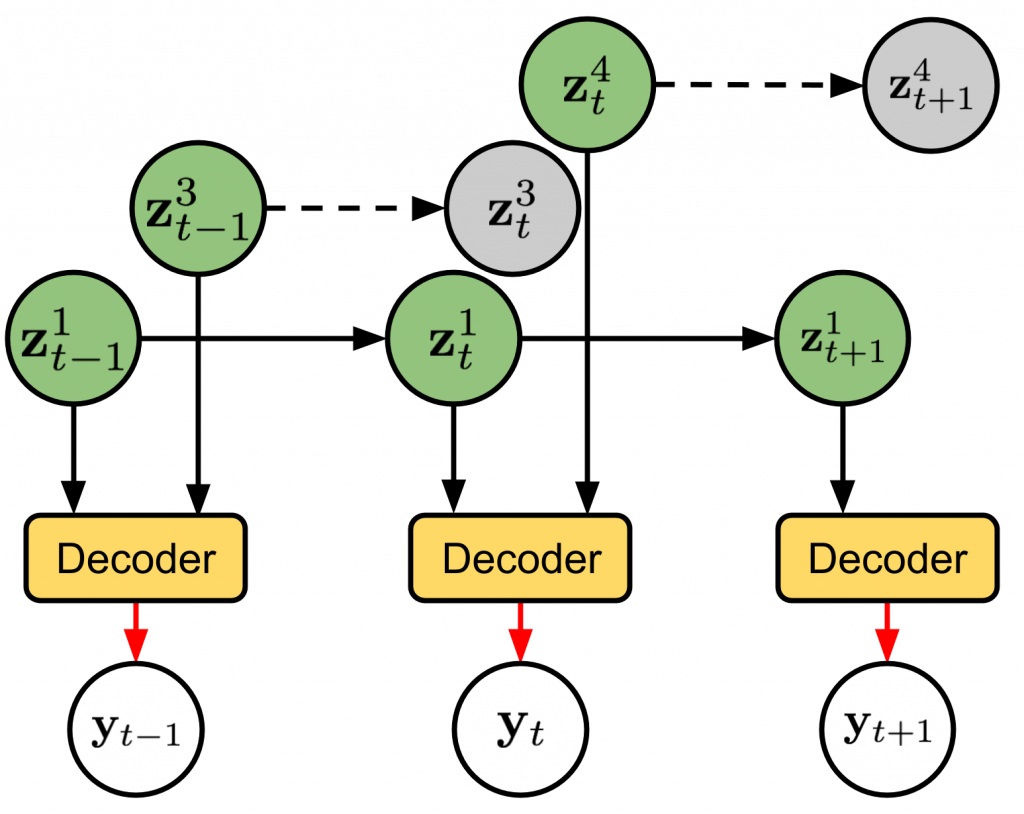
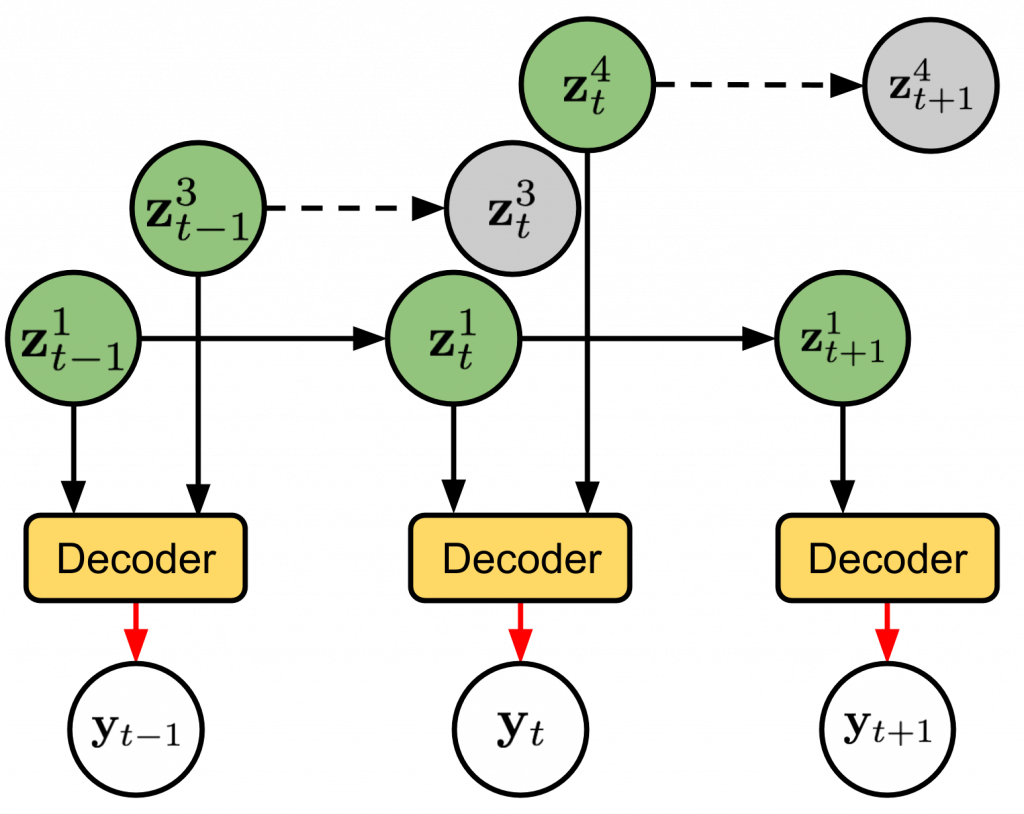
SQAIR is a neural generative model of moving objects. Objects can randomly appear, and once present, their state is propagated between video frames until they dissapear. SQAIR can be used for unsupervised object detection and tracking, and for model-based RL.
![[PDF]](https://ori.ox.ac.uk/wp-content/plugins/papercite/img/pdf.png) A. R. Kosiorek, H. Kim, I. Posner, and Y. W. Teh, “Sequential Attend, Infer, Repeat: Generative Modelling of Moving Objects,” arXiv preprint arXiv:1806.01794, 2018.
A. R. Kosiorek, H. Kim, I. Posner, and Y. W. Teh, “Sequential Attend, Infer, Repeat: Generative Modelling of Moving Objects,” arXiv preprint arXiv:1806.01794, 2018.



