11 May 2020
Imagine That! Leveraging Emergent Affordances for 3D Tool Synthesis
Imagine That! Leveraging Emergent Affordances for 3D Tool Synthesis
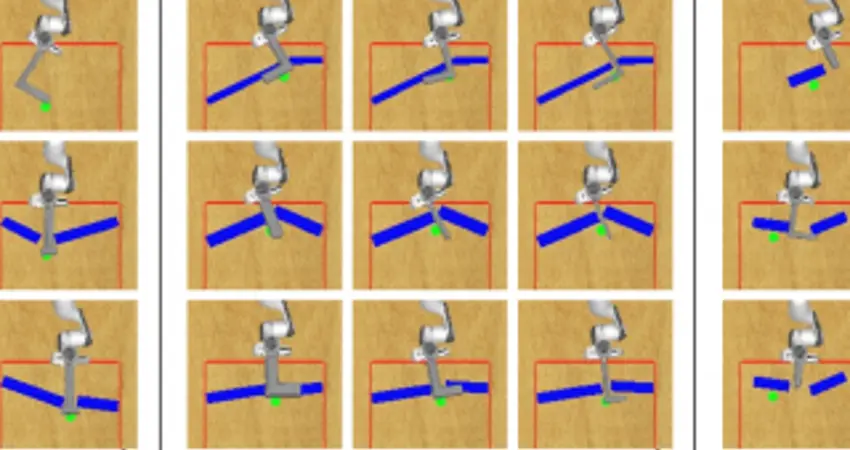
In this paper we explore the richness of information captured by the latent space of a vision-based generative model – and how to exploit it. The context of our work is an artificial agent’s ability to perform task-focused tool synthesis for 3D reaching tasks based purely on 2D visual inputs. In particular, given visual observations of a reaching task and a proposed tool, our approach employs activation maximisation of a task-based performance predictor to directly optimise the 3D geometry of the tool by traversing a learnt latent space. While the embedding learned by the generative model captures the factors of variation in 3D tool geometry, e.g. length, width and configuration, the performance predictor identifies sub-manifolds correlated with task success in a weakly supervised manner. Using a 3D simulation environment, we demonstrate that traversing the latent space in this task-driven way results in tool geometries appropriate for the task at hand.Our results therefore suggest that affordances – like the utility for reaching – are encoded along smooth trajectories in the learned latent space. Accessing these emergent affordances via gradient descent considering only high-level performance criteria (such as task success) enables the agent to manipulate tool geometries in a targeted and deliberate way.
Video: Imagine_ORI



