Depth Estimation for 3D Reconstruction and Robotic Navigation
Depth Estimation for 3D Reconstruction and Robotic Navigation
We use learning-based uncertainty-aware depth completion to densify sparse lidar measurements with vision. With the input of a 16-beam lidar and camera images, we can achieve reconstruction with explicit free space that’s similar to using a 64-beam lidar. Our method is deployed on a legged robot platform (Boston Dynamics Spot) with a multi-camera setup. The depth completion network could run on a mobile GPU at 10 Hz.
Publication
Y. Tao, M. Popović, Y. Wang, S. Digumarti, N. Chebrolu, and M. Fallon, “3D Lidar Reconstruction with Probabilistic Depth Completion for Robotic Navigation”, in IEEE/RSJ Intl. Conf. on Intelligent Robots and Systems (IROS), 2022. pdf(link TBC), video(link TBC)

Abstract
Safe motion planning in robotics requires planning into space which has been verified to be free of obstacles. However, obtaining such environment representations using lidars is challenging by virtue of the sparsity of their depth measurements. We present a learning-aided 3D lidar reconstruction framework that upsamples sparse lidar depth measurements with the aid of overlapping camera images so as to generate denser reconstructions with more definitively free space than can be achieved with the raw lidar measurements alone. We use a neural network with an encoder-decoder structure to predict dense depth images along with depth uncertainty estimates which are fused using a volumetric mapping system. We conduct experiments on real-world outdoor datasets captured using a handheld sensing device and a legged robot. Using input data from a 16-beam lidar mapping a building network, our experiments showed that the amount of estimated free space was increased by more than 40% with our approach. We also show that our approach trained on a synthetic dataset generalises well to real-world outdoor scenes without additional fine-tuning. Finally, we demonstrate how motion planning tasks can benefit from these denser reconstructions.
Approach
The inputs to our system are sets of grey-scale camera images and sparse lidar depth images. This input is processed by a neural network with a shared encoder and two separate decoders to generate a completed dense depth image and the corresponding depth uncertainty prediction. Our experiments used networks whose architectures are based on [1–3]. We filter unreliable depth predictions considering their range and predicted uncertainty. The remaining predicted depth and uncertainty are then fed into an efficient probabilistic volumetric mapping system [4, 5] to create a dense reconstruction.
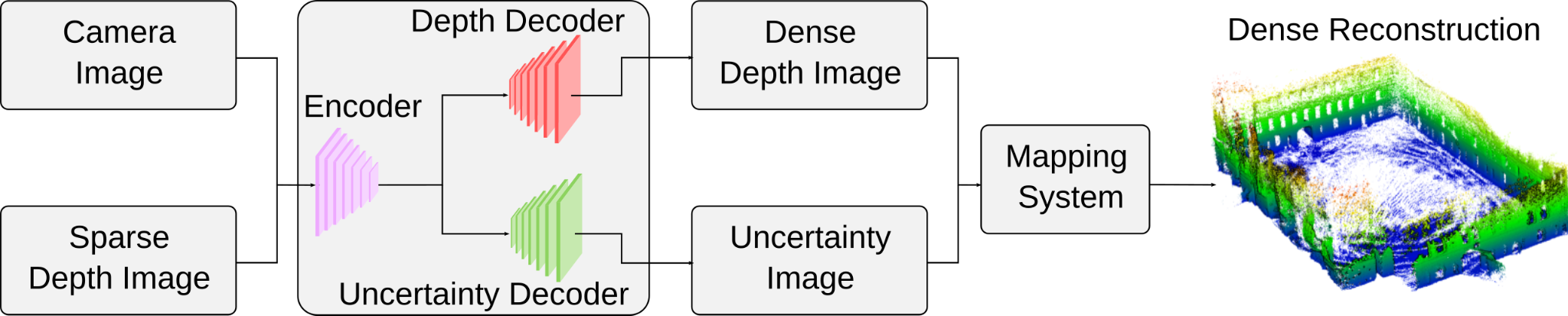
Robotic Platform
Most lidar depth completion works use only a forward-facing monocular camera image. Thus, around three-fourths of the lidar points are not considered during depth completion. Instead, we built a device with three Intel Realsense D435i cameras and a 64-beam Ouster lidar scanner. The three cameras were arranged to face front, left and right respectively. This device was mounted on a legged robot, Boston Dynamics Spot. This is our Mathematical Institute dataset.
Probabilistic Depth Completion
The probabilistic depth completion is trained using both synthetic datasets Virtual KITTI and our real-world Newer College Dataset (NCD). The depth network is trained with virtual KITTI, so that it benefits from large training samples and precise depth (including sky). The uncertainty decoder is trained on NCD, therefore it captures real-world depth characteristics.
The completed depth from the network is subject to outliers, which would then generate distorted reconstruction and false positive free space volumes in regions that are truly unknown or occupied. Thus, the uncertainty of the completed depth becomes crucial when deploying such a system in a robotic application. Our uncertainty decoder is trained to predict the error in the completed depth, which usually occurs around object boundaries. Completed depth with high uncertainty is then filtered before passing to the mapping system. This helps us to retain the accuracy of the reconstruction and detected free space.

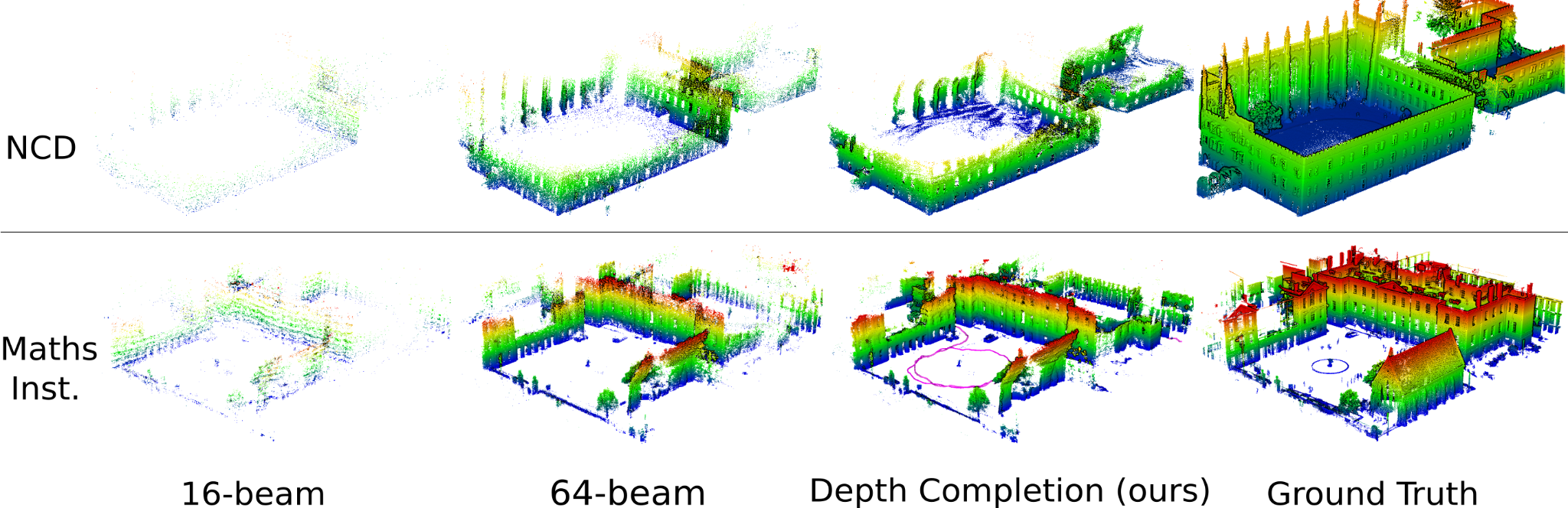
Reconstructions
We compare mesh reconstruction using different inputs
- 16-beam lidar
- 64-beam lidar
- depth completion
- ground truth point cloud captured by a laser scanner
for NCD with a monocular camera (top row) and Mathematical Institute dataset with multi-cameras (bottom row). Our reconstruction using completed depth recovers significantly more ground truth occupied space than the reconstruction with raw 16-beams, while retaining an average point-to-point error below 0.2 m.
The reconstruction using our approach with completed depth reveals much more correct free space than when using raw 16-beam lidar depth. The performance is similar to using the full dense 64-beam lidar.
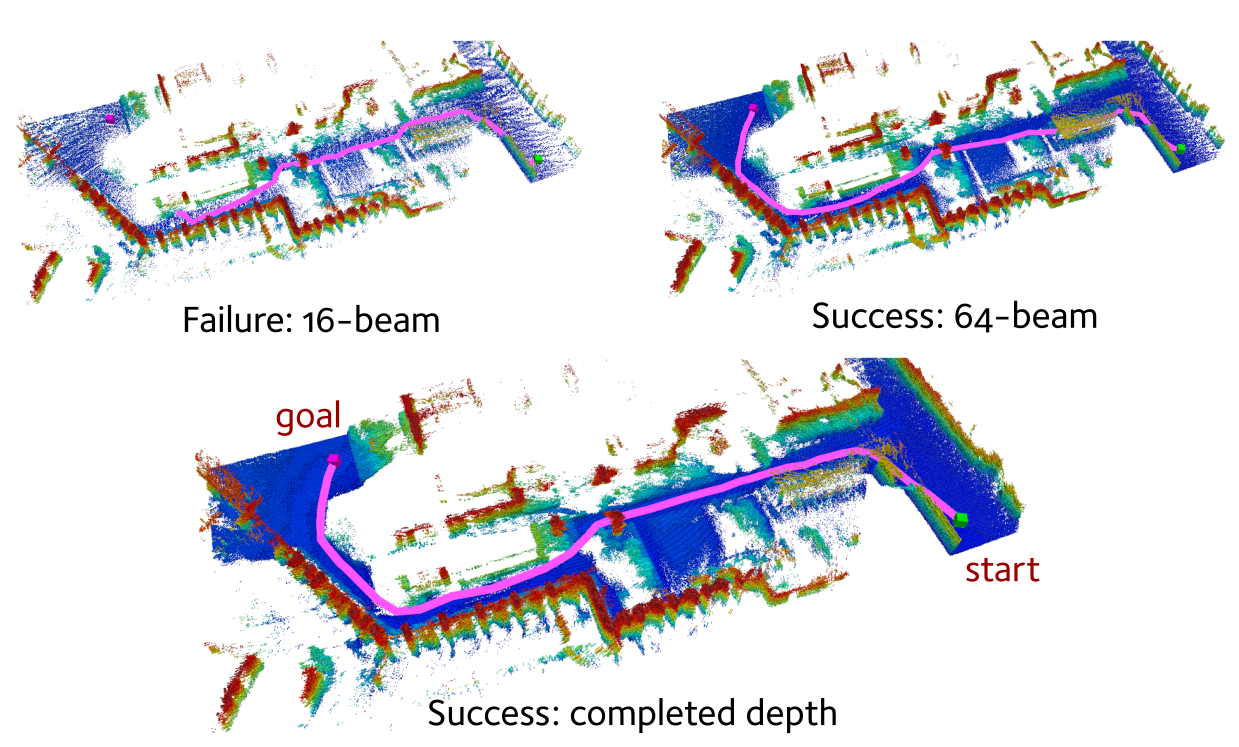
Application in Path Planning
We illustrate planning results using 64-beam, 16-beam lidar and completed depth as inputs respectively. We use the RRT* planner [6] to generate a path in the map that passes through narrow garden passages between two buildings. RRT* fails to find a path in the map created using 16-beam lidar, as its sparse measurement cannot detect sufficient free space. In contrast, the much denser reconstruction from our approach allows RRT* to find a path in the same scenario.
References
[1] F. Ma and S. Karaman, “Sparse-to-dense: Depth prediction from sparse depth samples and a single image,” in IEEE Intl. Conf. on Robotics and Automation (ICRA), 2018
[2] F. Ma, G. V. Cavalheiro, and S. Karaman, “Self-supervised sparse-to-dense: Self-supervised depth completion from LiDAR and monocular camera,” in IEEE Intl. Conf. on Robotics and Automation (ICRA), 2019
[3] D. Wofk, F. Ma, T.-J. Yang, S. Karaman, and V. Sze, “Fastdepth: Fast monocular depth estimation on embedded systems,” in IEEE Intl. Conf. on Robotics and Automation (ICRA). IEEE, 2019
[4] N. Funk, J. Tarrio, S. Papatheodorou, M. Popović, P. F. Alcantarilla, and S. Leutenegger, “Multi-resolution 3D mapping with explicit free space representation for fast and accurate mobile robot motion planning,” IEEE Robotics and Automation Letters, 2021.
[5] Y. Wang, N. Funk, M. Ramezani, S. Papatheodorou, M. Popović, M. Camurri, S. Leutenegger, and M. Fallon, “Elastic and Efficient LiDAR Reconstruction for Large-Scale Exploration Tasks,” in IEEE Intl. Conf. on Robotics and Automation (ICRA), 2021.
[6] S. Karaman and E. Frazzoli, “Sampling-based algorithms for optimal motion planning,” Intl. J. of Robotics Research, 2011.



