01 Nov 2019
Permutation Invariance and Relational Reasoning in Multi-Object Tracking
Permutation Invariance and Relational Reasoning in Multi-Object Tracking
Relational Reasoning is the ability to model interactions and relations between objects. A machine learning model performing relational reasoning often has access to a list of object representations. The ordering of the list could carry information for the task at hand, but that is not necessarily the case. Hence, in many cases, relational reasoning calls for permutation invariant (or equivariant) architectures. In End-to-end Recurrent Multi-Object Tracking and Trajectory Prediction with Relational Reasoning, we examine the importance of relational reasoning and the role of permutation invariance in a real world setting.
To do so, we build on Hierarchical Attentive Recurrent Tracking (HART), a recently-proposed, alternative method for single-object tracking (SOT), which can track arbitrary objects indicated by the user (Kosiorek et al. (2017)). This is done by providing an initial bounding-box, which may be placed over any part of the image, regardless ofwhether it contains an object or what class the object is. HART efficiently processes just the relevant part ofan image using spatial attention; it also integrates object detection, feature extraction, and motion modelling into one network, which is trained fully end-to-end. Contrary to tracking-by-detection, where only one video frame is typically processed at any given time to generate bounding box proposals, end-to-end learning in HART allows for discovering complex visual and spatio-temporal patterns in videos, which is conducive to inferring what an object is and how it moves.
In the original formulation, HART is limited to the single-object modality — as are other existing end-to-endtrackers (Kahou et al. (2017); Rasouli Danesh et al. (2019); Gordon et al. (2018)). In this work, we present MOHART, a class-agnostic tracker with complex relational reasoning capabilities provided by a multi-headedself-attention module (Vaswani et al. (2017); Lee et al. (2019)). MOHART infers the latent state of everytracked object in parallel, and uses self-attention to inform per-object states about other tracked objects. This helps to avoid performance loss under self-occlusions of tracked objects or strong camera motion. Moreover, since the model is trained end-to-end, it is able to learn how to manage faulty or missing sensor inputs. In order to track objects, HART estimates their states, which can be naturally used to predict future trajectories over short temporal horizons, which is especially useful for planning in the context of autonomous agents. MOHART can be trained simultaneously for object tracking and trajectory prediction at the sametime, thereby increasing statistical efficiency of learning. In contrast to prior art, where trajectory predic-tion and object tracking are usually addressed as separate problems with unrelated solutions, our work showtrajectory prediction and object tracking are best addressed jointly.

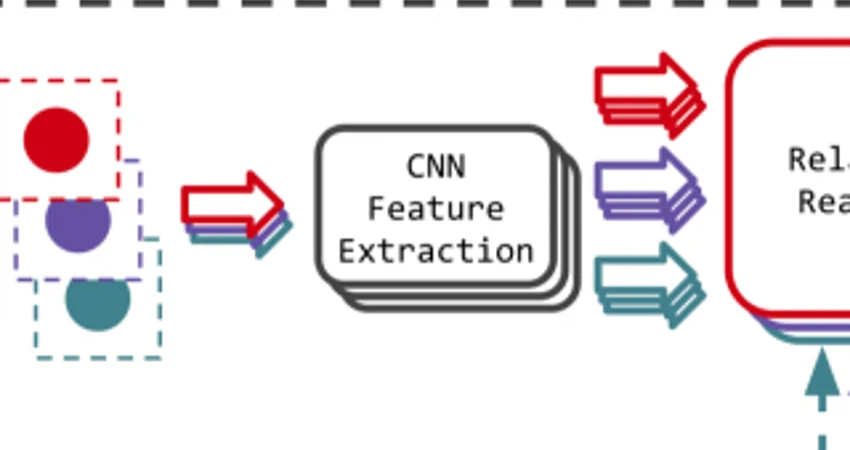
The figure above shows a sketch of the MOHART architecture. A glimpse is extracted for each object using a (fully differentiable) spatial attention mechanism. These glimpses are further processed with a CNN and fed into a relational reasoning module. A recurrent module which iterates over time steps allowsfor capturing of complex motion patterns. It also outputs spatial attention parameters and a feature vector per object for the relational reasoning module. Dashed lines indicate temporal connections (from time step t to t+1).
The entire pipeline operates in parallel for the different objects, only the relational reasoning module allows for exchange of information between tracking states of each object. We argue that this is a set-based problem: the ordering of the list of object representations carries no meaning for the task at hand. A naive way of introducing meaning to the order would be to leverage location information, which of course is highly relevant for relational reasoning. However, location information is two dimensional whereas a list is one dimensional and carries no information about distance. Hence, we argue that it is much more beneficial to include positional encoding into the object representations and use a permutation invariant architecture. In Section 3, we show that processing the information in a non-permutation manner shows no performance improvement compared to single object tracking (i.e. no relational reasoning), despite being theoretically capable of learning permutation invariance and having more capacity. We further show that, in this setting, the DeepSets architecture, which has been widely used and studied in the context of set-based problems, despite theoretically allowing for universal approximation of all permutation invariant functions, is inferior to multi-headed self-attention.
![[PDF]](https://ori.ox.ac.uk/wp-content/plugins/papercite/img/pdf.png) F. Fuchs, A. Kosiorek, L. Sun, O. Parker Jones, and I. Posner, “End-to-end Recurrent Multi-Object Tracking and Trajectory Prediction with Relational Reasoning,” in Sets and Parts Workshop at the Conference on Neural Information Processing Systems (NeurIPS), 2019.
F. Fuchs, A. Kosiorek, L. Sun, O. Parker Jones, and I. Posner, “End-to-end Recurrent Multi-Object Tracking and Trajectory Prediction with Relational Reasoning,” in Sets and Parts Workshop at the Conference on Neural Information Processing Systems (NeurIPS), 2019.



